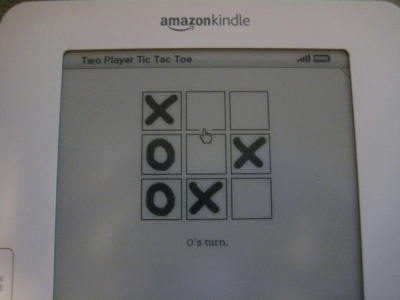
This doesn't mean that interactive games can't be developed in an e-book format. I developed a Tic Tac Toe (aka Noughts and Crosses) game for the Kindle by writing code that pumps out an HTML file containing every playable board. The board exists as a set of 9 images - the empty squares are links to a page with a board that contains the current player's mark on that square. The version I made first (Two Player Tic Tac Toe at the Kindle Store) is a two player game - the first player makes a move and then hands it off to the 2nd player. The e-book is over 5000 pages long and allows every possible move in a Tic Tac Toe game. It was easy to develop, and the code is explained below.
There is at least one other e-book game available in the Kindle store, The Towers of Hanoi Puzzle. This puzzle works on a similar principle - each page contains links that take you to a page containing the next game state.
The code
The source code for an early version of the Two Player Tic Tac Toe (TPTTT) HTML generator is available here. It's C#, which isn't quite as sexy as Haskell or Clojure or whatever is popular on proggit nowadays, but it worked for me.Board State Representation
A game board is represented by a Board class that has one instance member - a 9 element array of ints that holds the state for each square on the board. A zero means the square is empty, -1 means an X, -2 means an O, and any positive integer is the index into an array of Boards that contains the board state for that move.The board array is just that - an array. Many people will use a tree structure for doing things like this, but I chose a flat array with each board indexed by an integer representing its state. Every possible game state can be represented by a ternary (base-3) integer - each digit is a 0, 1, or 2. In my code an empty square zero, X is 1, and O is 2. The most significant trit of the ternary number is in the top-left square. Here's a graphic to explain how it works:
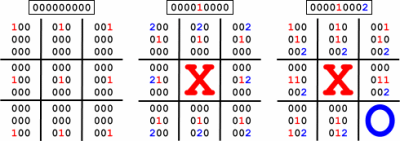
The 9 digit numbers in each of the squares are the ternary representation of what the board will look like if the current player chooses that square. That number is also the index of that board in the array of boards. In the picture, the first board has an index of zero and each of the empty spaces are links to new boards where X places his mark there. If X chooses the middle square, the 2nd board is 000010000 in ternary, 81 decimal, or 0x51 hex. Now each empty square has a link to the board where O chooses that spot. If O picks the lower right corner, that board is index 000010002 ternary (83 decimal, 0x53 hex).
The maximum possible board states is 39, or 19683, but there are many fewer possible boards in a game of Tic Tac Toe. For example, the highest index possible here - with a board full of O's - just won't happen in a game. Each board will always have a number of X's that is either equal to the number of O's or one more than that. A game will never continue once it's been won. The total number of possible individual boards for the two player game is 5474. This number of boards is able to represent all 255,168 possible playable games. It's possible to further trim the number of boards needed by not continuing game states that will always end in a tie, but the code posted here doesn't do that.
Generating the HTML
There are two phases to the execution of the code - first all of the board states are created, then the HTML representation is printed.Each game board is generated in the NextTurn method which calls itself recursively. It's simply a loop that goes through each of the 9 spaces on the board looking for an empty space. If it finds one (not containing an X, a O, or an address) it makes a move there. When a move is made, the resulting board state is stored in the boards array based on its index. There is a bit of an optimization in the code where it won't re-create a board state that already exists. It's kind of pointless to optimize code like this that's designed to run once and finishes in under a second, but I couldn't handle the fact that it was so inefficient and my willpower is weak.
When NextTurn determines that there's a tie or a winner on a given board, it returns. Once all of the game boards have been calculated, the next phase of the program loops through the entire array of boards looking for non-null entries at each index. When it finds one, the board is printed as HTML that looks like this:
<a name="0"></a> <table border=1><tr><td><a href="#1">_</a></td><td><a href="#3">_</a></td><td><a href="#9">_</a></td></tr><br/> <tr><td><a href="#1b">_</a></td><td><a href="#51">_</a></td><td><a href="#f3">_</a></td></tr><br/> <tr><td><a href="#2d9">_</a></td><td><a href="#88b">_</a></td><td><a href="#19a1">_</a></td></tr><br/> </table><br>Every board has an anchor tag who's name is the index of the board (it's not actually legal for a name token to start with a digit, but the Kindle and most browsers don't seem to mind). Each empty entry contains a link to the board that contains that move. A board that contains a winner has no links and displays a helpful message indicating that someone one.
The code posted here prints the results as HTML tables, and empty spaces are underlines. The 'production' code that generates the 'real' e-book uses a set of square images to represent the X's, O's, and empty spaces.
You can check out the full HTML here. It's about 1.3mb. It works best in a web browser if you shrink the window down so you can only see the immediate board you're on and the space below it.
The e-book
Once the HTML was generating properly, a lot of time was spent making it look good on the Kindle. I replaced the HTML tables with sets of images. I inserted pagebreaks using a special HTML tag that exists for this purpose. It took a while to tweak the images to get them to line up properly and to allow for easy movement with the Kindle's controller. The size was pretty huge (550KB) but I managed to shrink it down to around 480KB (still huge) with some creativity - mostly by removing unneeded HTML tags.Single Player Tic Tac Toe
I also developed a single player version of Tic Tac Toe that allows you to play against "the computer". This version of the e-book contains 16 random starting games. The player picks one of the games which takes them to a page where either they can make the first move or the computer has already made the first move. The computer moves are picked using the NegaMax algorithm, with a random element added to let the player win occasionally.Because the number of boards doesn't need to account all possible moves of two players - just one, the number of boards required to represent a game is much smaller than the two player game. If the computer goes first, there are an average of around 200 boards needed. When the player goes first, around 400 are needed. The code that generates the single player TTT e-book produces 16 different games where either the user goes first or the computer goes first. The first player is split up 50/50, and the computer's starting point is always random (instead of the best spot - the middle square).
If you want to try out a single player version of e-book Tic Tac Toe, download this demo. I tested it on Kindle and Mobipocket Reader, but it may work on other readers. The full version is available from the Kindle Store here.
Update: This concept was also explored by Thomas Jansen at http://blog.beef.de/2008/01/16/html-game/

